The objects that machine learning deals with have some underlying geometric structure. For example, the meaning of an object in an image does not depend on its position. This property is called translational symmetry, and convolutional neural networks are designed to preserve it, exhibiting high performance in image recognition. This kind of approach is specifically referred to as geometric deep learning. Other properties such as topology and metrics of data distribution are also crucial for generation and edit of data more precisely according to users' intentions. The focus on the geometric structures is essential for improving both performance and reliability.

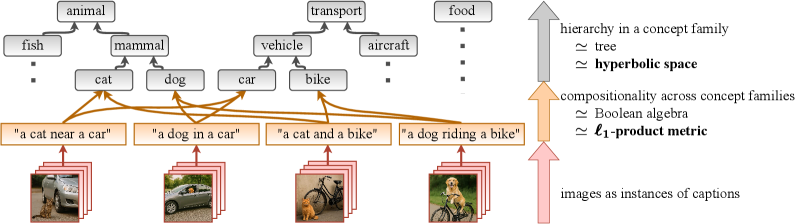
Vision-language models have used hyperbolic space to capture hierarchy within a concept family (e.g., dog is-a mammal), but it struggles to express compositionality across different concept families at the same time (e.g., a dog in a car). We propose PHyCLIP, which introduces an ℓ1-product metric on a product of hyperbolic spaces. Each space captures hierarchy within a single concept family, and the ℓ1-product metric handles cross-family composition.
World models support sample-efficient deep reinforcement learning but struggle in high-dimensional, non-stationary environments with multiple interacting objects because they learn holistic representations. We propose STICA, a unified framework with object-centric Transformers as the world model and causality-aware policy and value networks. STICA represents observations as object-centric tokens along with action and reward tokens, enabling token-level dynamics and interaction prediction. The policy and value networks estimate token-level cause–effect relations and use them in attention layers to guide decision-making. Experiments on object-rich benchmarks show consistent improvements in both sample efficiency and final performance.

Diffusion models can generate diverse and creative images with high quality, but they often fail to accurately reproduce the intended content of the text. For example, specified objects may not be generated, adjectives may incorrectly modify unintended objects, and relationships indicating ownership between objects may be overlooked. In this study, we proposed Predicated Diffusion. This method expresses the intent of the text as propositions using predicate logic, considers attention maps inside the diffusion model as corresponding to fuzzy logic, and thereby defines a differentiable loss function that evaluates the fidelity. Evaluation experiments with human evaluators and trained image-text models demonstrated that the proposed method can generate images faithful to various texts while maintaining high image quality.
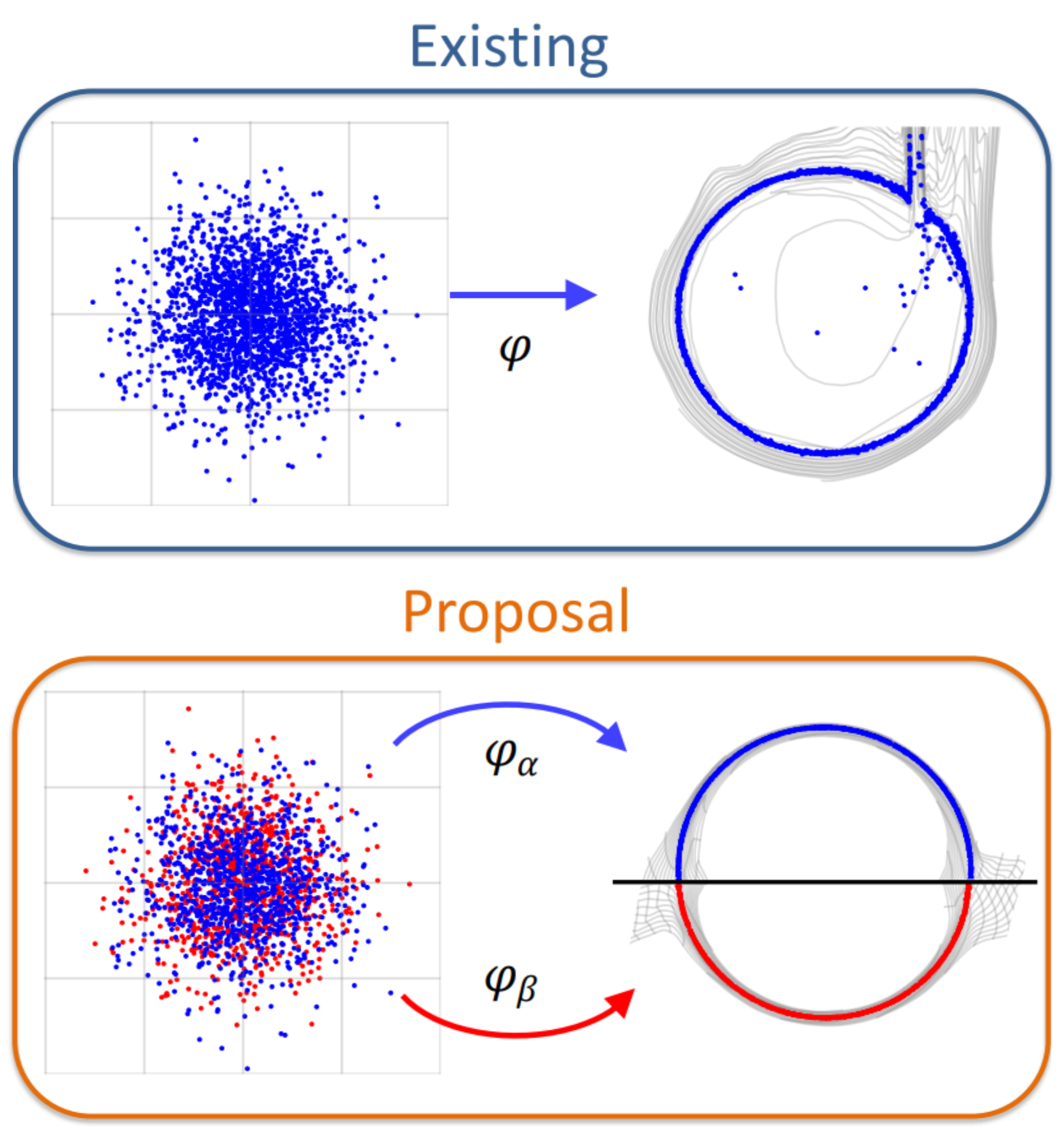
Deep generative models, such as GANs, enable us to freely edit the attributes of generated images (e.g., age or hair length for human faces) by adding specific attribute vectors to latent variables. However, real data distributions often have biases and distortions, which also affect the distribution of corresponding latent variables, and simple linear operations do not provide satisfactory results. Some methods define vector fields in the latent space and move latent variables along these flows to edit images nonlinearly. While this approach can improve editing quality, its editing are generally non-commutative, that is, "turning the face sideways and then making it smile" is often different from "making the face smile and then turning it sideways." In this study, we define commutative vector fields in the latent space, via defining curvilinear coordinates by appropriately distorting Cartesian coordinates using deep learning, to ensure the commutative and nonlinear editing. Experiments demonstrated that our approach not only enables order-independent and high-quality editing but also promotes the disentanglement of different attributes during learning.
Point clouds are a representation of 3D data that are higher resolution than voxels and easier to handle than meshes. Learning point cloud generation models is expected to be useful for a wide range of tasks such as reconstruction and super-resolution. Point clouds usually represent the surface of an object, so they have topologically distinctive structures such as cavities and holes. However, existing generation models do not consider such structures and generate them as a single mass, which makes it difficult to accurately represent cavities and causes protrusions to be crushed. Therefore, we proposed a method to generate point clouds in parts using a conditional generation model, as if covering a manifold with multiple local coordinate systems. We designed it so that the computational cost does not increase even if the number of conditions increases by using the Monte Carlo method with the Gumbel-Softmax approach. Compared to existing research, we demonstrated that it is possible to generate various 3D point clouds with different structures, such as cavities and protrusions, with high accuracy.
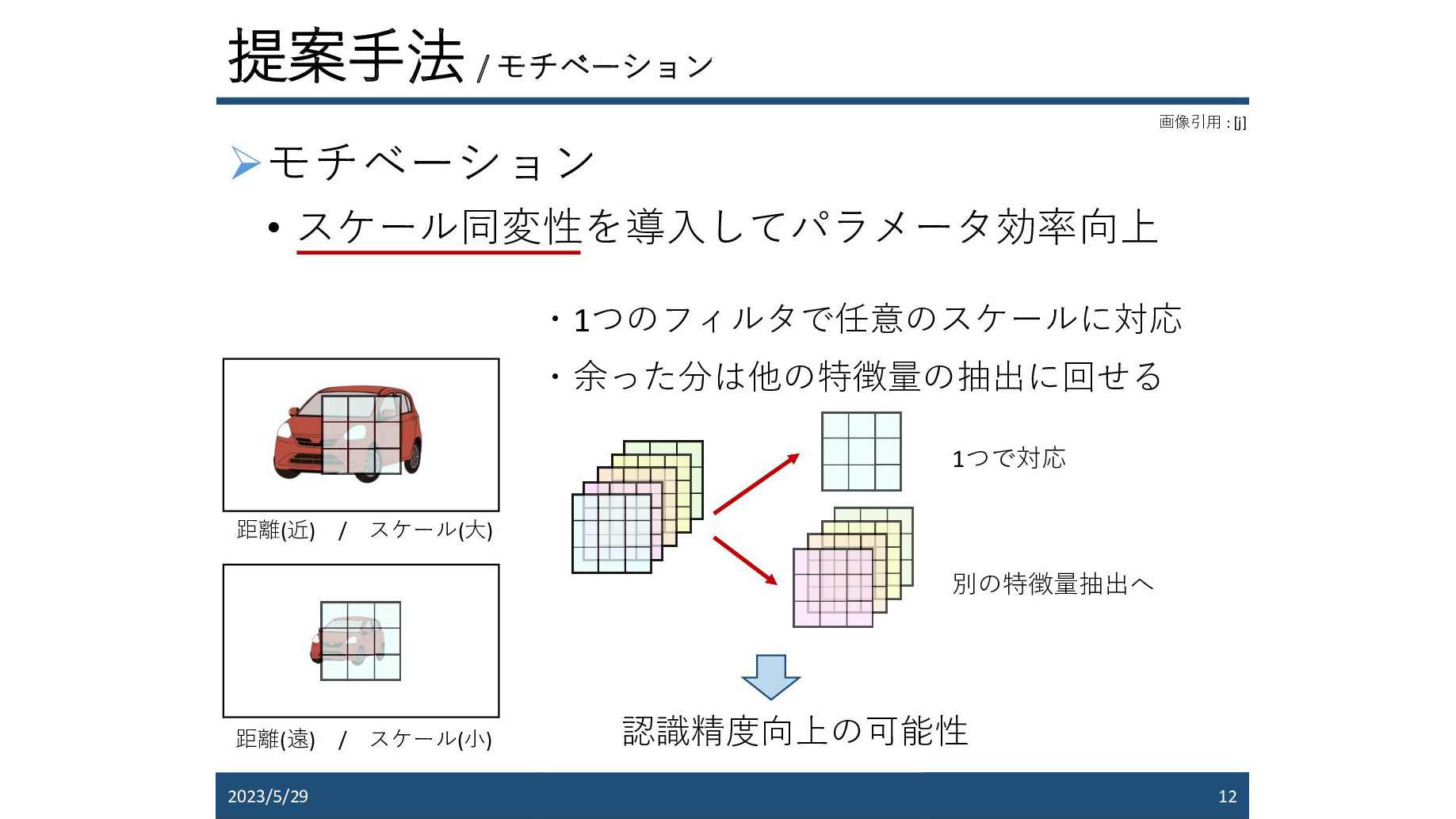
Accurate and robust environmental understanding is required to realize autonomous driving. Point cloud segmentation using LiDAR is attracting attention as a task for this purpose, and various methods have been proposed. Among them, the approach of projecting LiDAR point clouds onto a spherical surface to convert them into 2D distance images and then applying convolutional neural networks has become mainstream due to its efficiency and ease of design. In images, distant objects are represented smaller than nearby objects. Therefore, different types of convolution filters respond within the convolutional neural network. In other words, it is necessary to learn convolution filters that correspond to all sizes, which may reduce the efficiency and generalization of the convolutional neural network. Therefore, focusing on the inverse proportional relationship between the distance to the object and the scale ratio in the image, we propose distance-equivariant convolution that improves scale equivariance by using the same weight filter for different sizes by applying differential operators appearing in partial differential equations. By incorporating the proposed method into existing LiDAR point cloud segmentation networks, we confirmed performance improvement and actual equivariance.
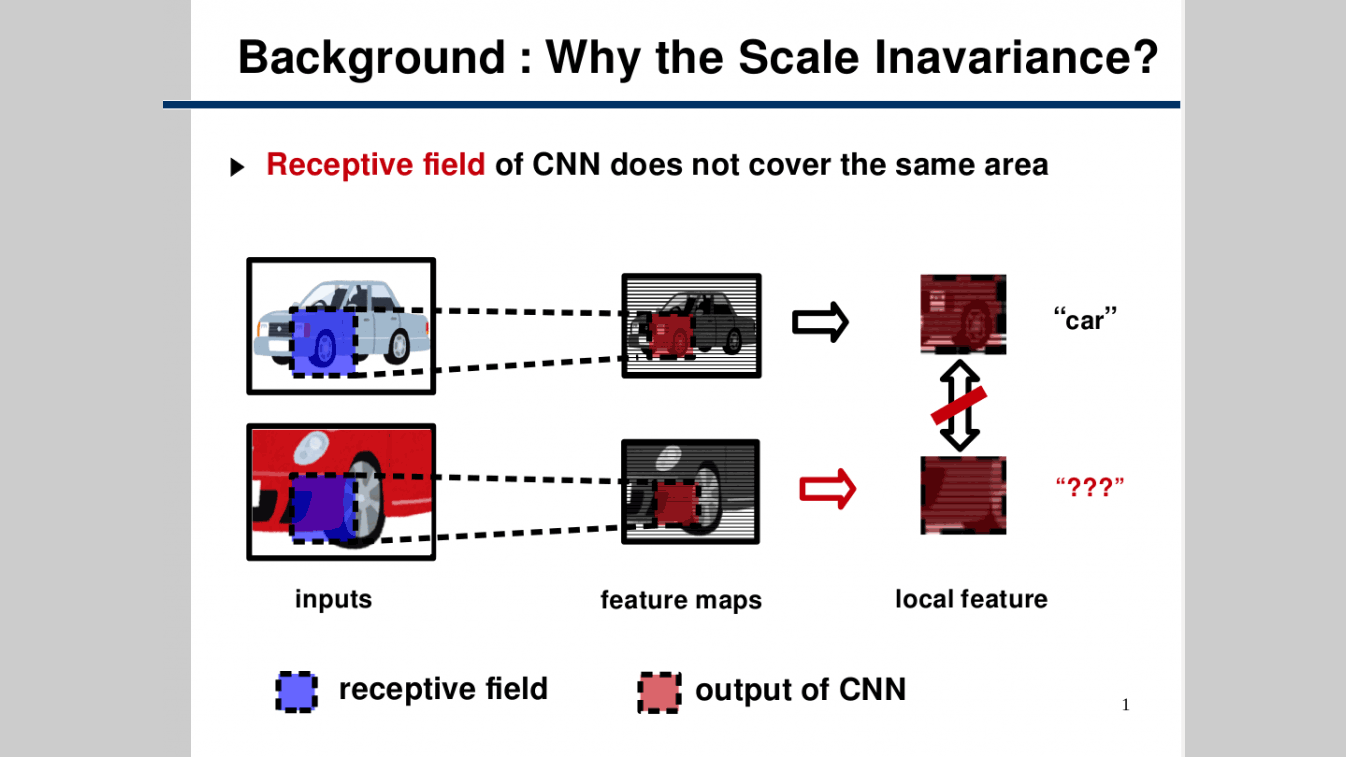
One of the particularly active research areas in deep learning in recent years is the development of multi-layer convolutional neural networks (CNNs) based on the spread of GPUs. Such multi-layered CNNs have achieved significant results, especially in the field of image recognition. It is known that these CNNs have translational invariance, which means they are robust to small translations of the object being imaged. However, it is also known that they are vulnerable to other geometric transformations such as scaling and rotation, which hinders the improvement of recognition accuracy. Therefore, in this study, we aimed to achieve scale invariance and further improve accuracy by equivalently handling feature information obtained from multiple scaled inputs with a new multi-stage network.