ベイズ深層学習(Bayesian deep learning)とは,ベイズ的モデル化に基づいて深層学習を設計する手法です. なかでも深層生成モデルは,データ間の因果関係や依存関係をベイジアンネットワークというグラフ形式で表し,その関係を深層学習で実装したものです. 出力結果の根拠の可視化,意思決定の信頼性(不確実性)の定量化,小規模データの効率的な解析などが可能になります. また生成AIの基盤技術の一部でもあります.


脳機能画像は問診による精神疾患診断を補佐し,客観的・定量的基準を与えると期待されます. しかし,データ収集には莫大なコストがかかり,通常の深層学習に必要な程度のデータセットはほとんど存在しません. さらに,年齢や性別といった個人差は病気に関連する活動パターンより顕著であり,適切な処理を行わなければ,男女で発症率の異なる疾患の特徴と身体的な性差を混同するなどの問題が生じます. また病院ごとの撮影機材の差も大きな混乱を招きます. そこで深層生成モデルを用いてベイジアンネットワークを構成し,精神疾患に関連する活動パターンと,年齢・性別などの個人差や機材差とを同時にモデル化します. 疾患や個人差は変化しないため,どの要因がどの情報を生むかを自動で学習し,精神疾患と個人差・環境差を高精度に区別できるようになります. これによって,複数の小規模データを集めて大規模データのように解析することが可能になり,性別・年齢に対して堅牢な高い精度での疾患の診断や,原因部位の可視化が可能になります.
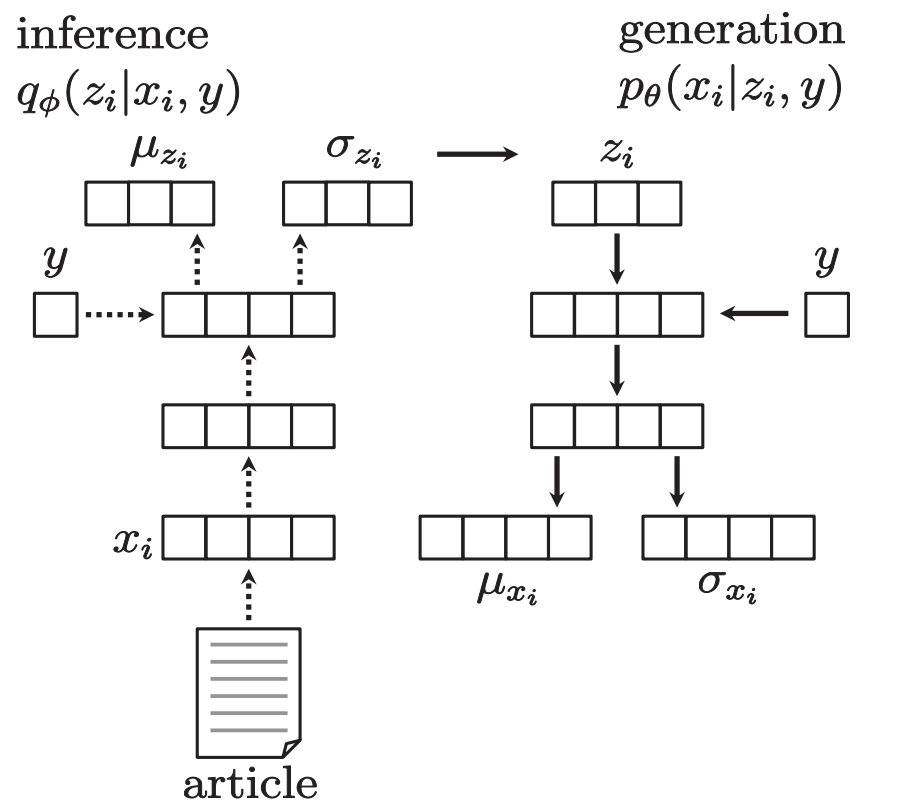
本研究では,深層生成モデルを用いてニュース記事から株価動向の日次予測を行う手法を提案する.複数ニュースそれぞれが持つ影響の大きさを考慮する.まずニュース記事が持つ情報を固定長のベクトルで表現するために,Paragraph Vectorと呼ばれる手法を用いる.これにより言語が持つ情報を十分に表現できる.次に株価情報と言語情報が持つ関係性を深層生成モデルで表現し,分散表現を基にパラメータを学習する.生成モデルを用いることにより,ニュース記事を生成する潜在変数や確率過程を表現でき,その表現に必要なパラメータの過学習を抑えることができる.実際に,日本市場とアメリカ市場の2市場を対象に,株価動向の2値分類を行い,本手法の有効性を示した.

深層学習の自動運転やロボット制御への応用研究が活発化しています. これらの実問題には膨大で多様な現データが必要ですが,夜間や雨天など多様な環境データを集めるには大きなコストがかかります. 環境シミュレータを構築してデータを得る方法もありますが,実環境との差が性能の劣化を招きかねず,高精度なシミュレータの開発にも大きなコストがかかります. そこで本研究では昼と夜など実データのモダリティを変換することで,学習データを水増しする方法を開発しました. 本研究は株式会社豊田中央研究所ト様との共同研究の一環として実施しました.
「異常検出」は画像分析で重要なタスクで,不良品検査や医療画像診断などに応用されます. 深層生成モデルを用いることで,画像など高次元の実データの尤度を推定でき,異常品のような数少ないデータは尤度が低いので,それをもって異常検出を実現できます. しかし,新製品など学習データに含まれない正常品も当然尤度が低くなり,異常品として検出されます. そこで製品グループごとに固有の特徴と,個々の製品に固有の特徴に分離する深層生成モデルを提案し,既存製品で学習したモデルを活用して少数の新製品データの異常品を発見する「few-shot異常検出」を実現しました. 本研究は株式会社地球快適化インスティテュート様との共同研究の一環として実施しました.

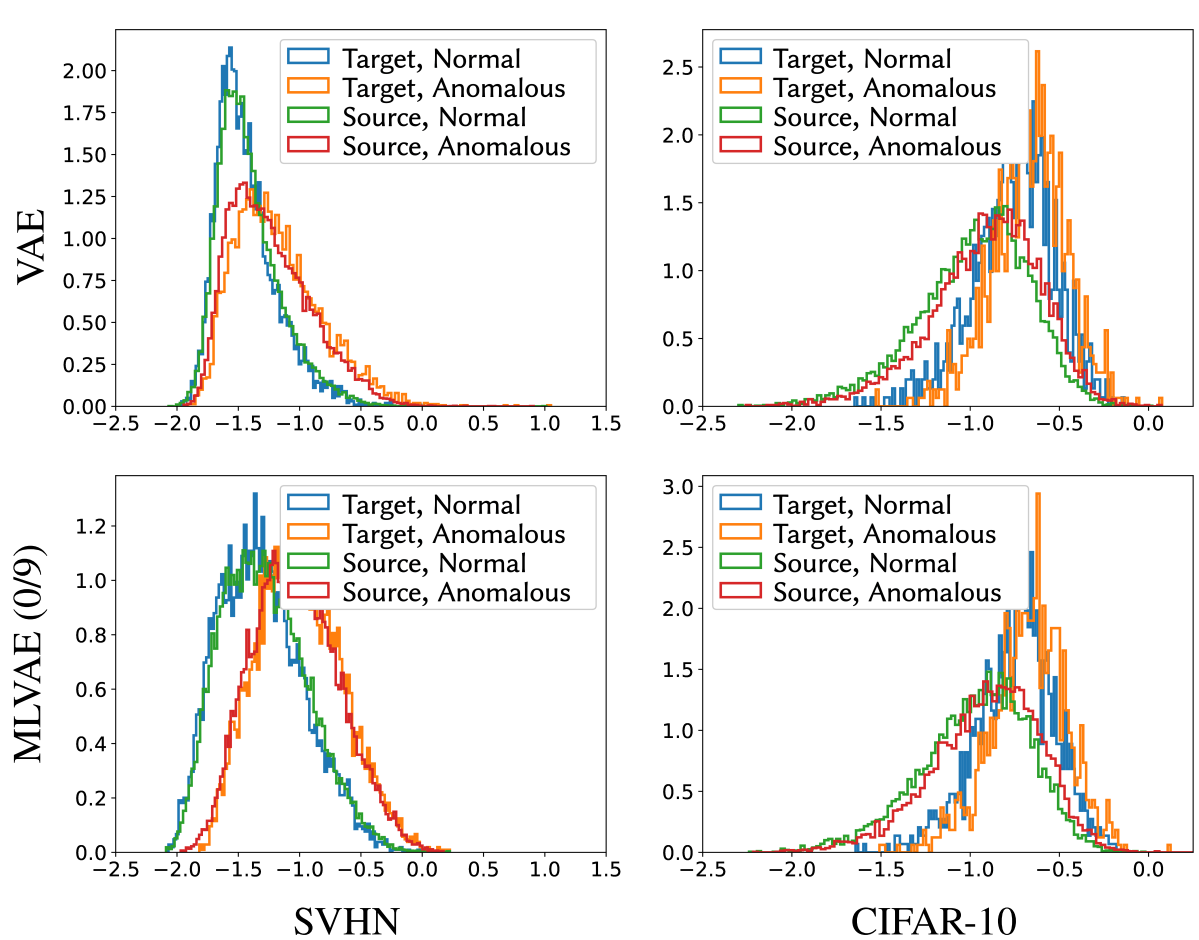
一般的に異常検出は,大量のデータから頻度が低いものを「異常」とみなします. 深層生成モデルは画像などを圧縮・復元するため,典型的なデータを優先的に学習し,復元できなかったものを異常と見なすことで異常検出を実現します. しかし,復元の失敗には「経験的不確実性(学習不足によるもの)」と「偶然的不確実性(ノイズや形状の複雑さによるもの)」があり,後者が高い部分(例:ネジ穴など)は正常でも誤検出が起こります. そこで,深層生成モデルの尤度を分解し,経験的不確実性に相当する項(非正則化異常度)のみを異常検出に使う手法を提案しました. これにより見た目の複雑さに惑わされずに異常を検知し,高精度化を実現しました. 本研究はアイシン・エィ・ダブリュ株式会社様との共同研究の一環として実施しました.
Qiitaに解説記事を書いてくださった方がいらっしゃいました.ありがとうございます.
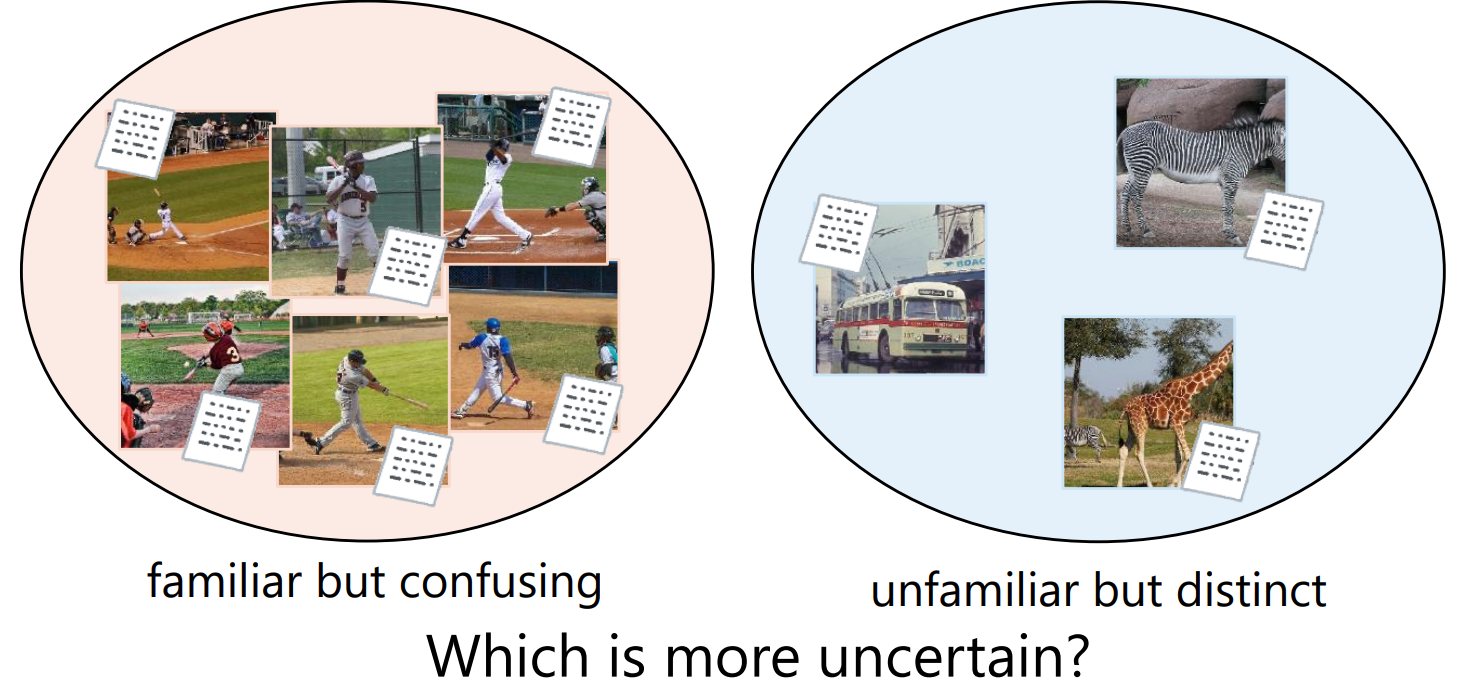
機械学習アルゴリズムで出力結果の信頼性をいかにして評価するかは大きな課題です. 分類問題・回帰問題においては,ベイジアンニューラルネットワークの出力の不確実性によって信頼性を評価する方法が提案されていますが,そのままでは画像テキスト検索には使えません. 本研究では画像テキスト検索を分類問題としての解釈(事後分布の不確実性),回帰問題としての解釈(埋め込み点の不確実性)により二つの不確実性を定義しました. その結果,分類問題としての解釈の方がより適切に信頼性を評価できていることを確認しました.

ニューラルネットワークは複雑な表現を学習することができ,様々なタスクで高い性能を示している.しかし,学習に利用できるデータは限られているため,過学習を起こしやすい.過学習を防ぐためにニューラルネットワークの学習を正則化することは,最も重要な課題の1つである.本研究では,大規模な畳み込みニューラルネットワークを対象とし,ハイパーネットを用いて,パラメータの事後分布を暗黙的に推定することで学習を正則化する.また,パラメータの分布が学習されることから,モデル平均化により識別精度を向上させることができる.