Bayesian deep learning is an approach that designs deep learning based on Bayesian modeling. In particular, deep generative models represent causality and dependency among observations using a graph structure called a Bayesian network, and then implement those relationships with deep learning. This allows us to visualize the interpretable rationale behind outputs, quantify the reliability (or uncertainty) of decision-making, and efficiently analyze small datasets. It is also part of the foundational technology behind generative AI.


Brain functional imaging is expected to supplement the diagnosis of mental disorders based on clinical interviews by providing objective criteria. However, data collection is extremely costly, and existing datasets are very small at the scale required for standard deep learning. Furthermore, individual variability such as age and gender often hinders detecting disease-related activity patterns. Additionally, discrepancies in imaging equipment across hospitals can cause further complications. To address these issues, we construct a Bayesian network using a deep generative model that simultaneously captures both the disease-related activity patterns and individual/environmental variability separately. As a result, multiple small datasets can be pooled and analyzed as if they were a single large dataset, accelerating robust, high-precision diagnosis robust to gender and age variations, as well as identifying of the disease-related regions.
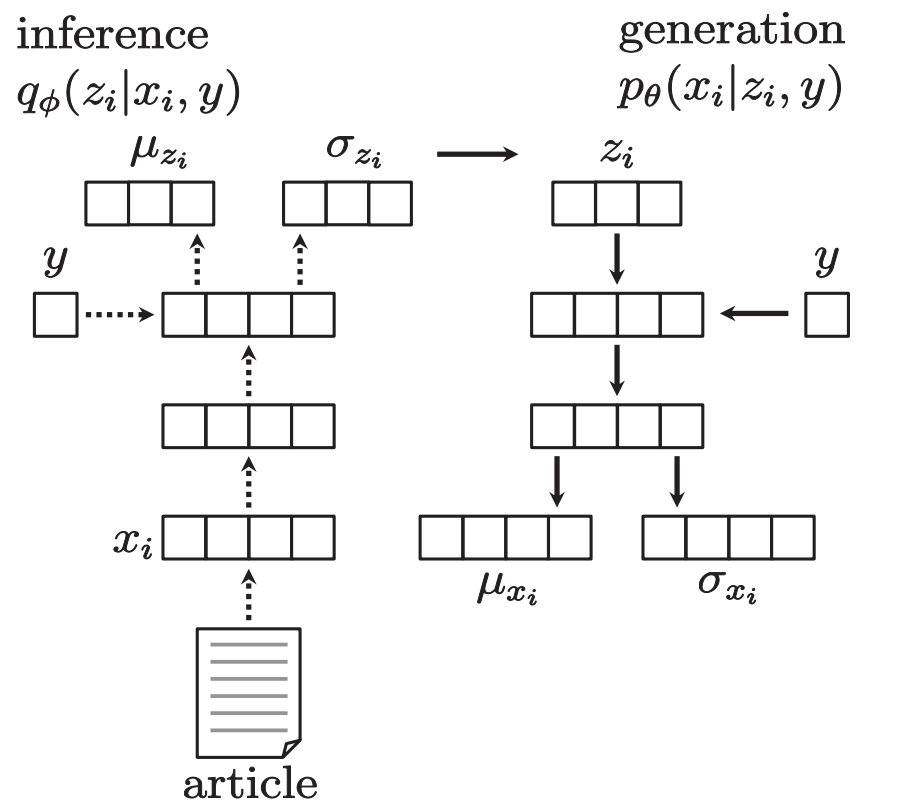
In this study, we propose a method for daily stock price trend prediction from news articles using deep generative models. We consider the impact of each news article. First, we use a method called Paragraph Vector to represent the information in news articles as fixed-length vectors, which sufficiently captures the information in the language. Next, we represent the relationship between stock price information and language information using deep generative models and learn the parameters based on the distributed representation. By using generative models, we can represent latent variables and probabilistic processes that generate news articles, and suppress overfitting of the parameters required for that representation. We demonstrated the effectiveness of this method by performing binary classification of stock price trends for both the Japanese and American markets.

Deep learning has been intensively investigated for autonomous driving and robotic control. These real-world problems require massive and diverse datasets, but collecting data for a wide range of conditions (such as nighttime and rainy weather) incurs significant costs. Although one approach is to develop environmental simulators to generate artificial data, discrepancies from real environments can degrade performance, and building a high-fidelity simulator itself is expensive. To overcome these challenges, this study proposes a method to augment training data by transforming real data modalities (that is, converting daytime data into nighttime data). This research was conducted as a joint research project with Toyota Central R&D Labs., Inc.
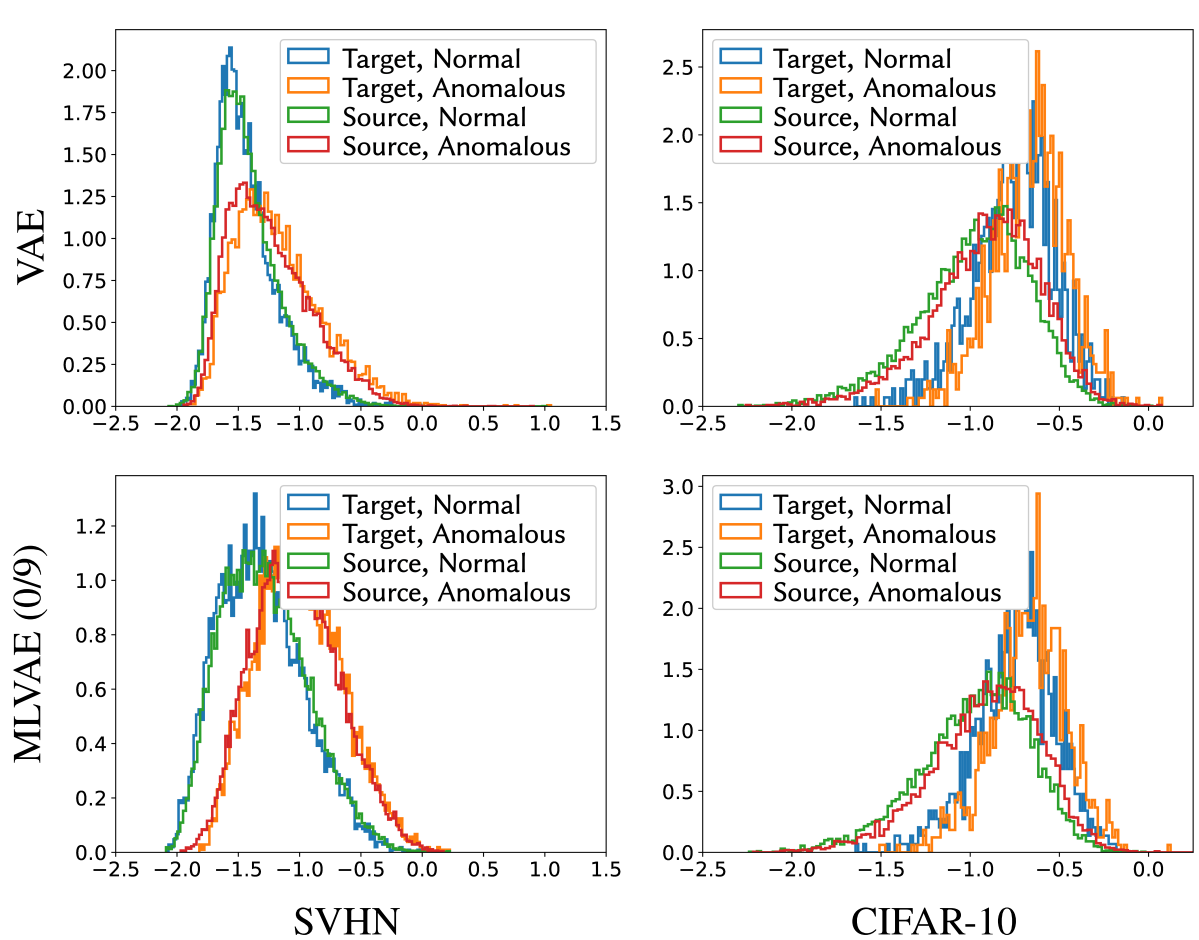
"Anomaly detection" is an important task in image analysis, with applications ranging from defective product inspection to medical imaging. Deep generative models enable estimation of the likelihood of high-dimensional real data, such as images, and rare samples (e.g., defective items) tend to have lower likelihood, making them detectable as anomalies. However, normal yet unseen products (e.g., newly developed products not included in the training set) also exhibit lower likelihood and are thus falsely detected as anomalies. To address this issue, we propose a deep generative model that separates features unique to each product group from those unique to individual items. Leveraging a model trained on existing products, our approach achieves "few-shot anomaly detection," thereby enabling the identification of defective items even among a small number of new product samples. This research was conducted as a joint research project with The KAITEKI Institute, Inc.

In general, anomaly detection refers to identifying rare instances within large datasets as "anomalies." Deep generative models, which learn to compress and reconstruct samples such as images, primarily learn typical samples and regard samples that cannot be reconstructed as anomalies. However, reconstruction failure may stem from "epistemic uncertainty" (due to insufficient training of rare samples) or "aleatoric uncertainty" (due to noise or complex shapes). Regions with high aleatoric uncertainty, such as screw holes, are frequently misdetected as anomalies despite being normal. To mitigate this problem, we decompose the likelihood in a deep generative model and uses only the component corresponding to epistemic uncertainty, termed the non-regularized anomaly score, for anomaly detection. This approach avoids being misled by visually complex regions, thereby improving detection accuracy. This research was conducted as a joint research project with AISIN AW Co., Ltd.
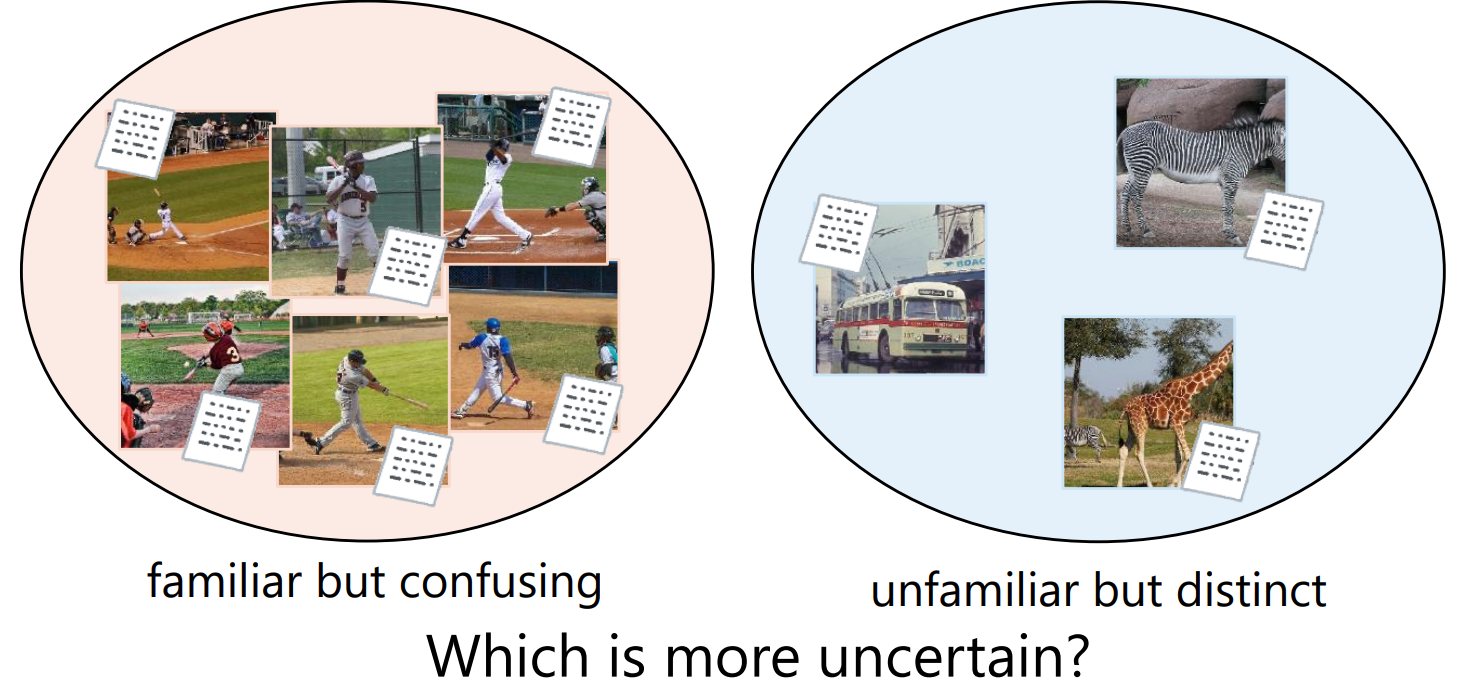
Evaluating the reliability of decision making of machine learning algorithms remains a major challenge. While uncertainty-based methods in Bayesian neural networks have been proposed for assessing reliability in classification and regression tasks, these methods cannot be directly applied to image-text retrieval. In this work, we define two types of uncertainty by interpreting image-text retrieval as a classification problem (posterior uncertainty) and as a regression problem (uncertainty in the embedding). Through experimentation, we found that treating image-text retrieval as a classification problem provides a more appropriate evaluation of reliability.

Neural networks can learn complex representations and show high performance in various tasks. However, since the data available for training is limited, they are prone to overfitting. Regularizing the training of neural networks to prevent overfitting is one of the most important challenges. In this study, we target large-scale convolutional neural networks and use hypernetworks to implicitly estimate the posterior distribution of parameters to regularize training. Additionally, since the distribution of parameters is learned, classification accuracy can be improved through model averaging.